
Experiments in Coding with AI
Fatal Exception: Developer Does Not Exist

AI code generation tools are profoundly reshaping how software is built. This post reflects on my hands-on experiences with tools like Lovable, Cursor, and ChatGPT, compares design-led and engineering-led approaches, and introduces a combined workflow that I have found delivers working web applications fast.
Code generation AI tools have become mainstream this year. They offer a fast track from text prompts to functional software, improving developer productivity and lowering the barrier to entry for software development. These tools are best understood through hands-on use. Prompting code into existence is, fundamentally, an act of experiential learning. While reading about it in posts like this one offers a useful introduction, meaningful understanding comes from direct engagement.
My notes are a personal write-up based on three months of using various coding AI tools. A note of caution on this. The field is evolving rapidly with new LLMs regularly being released and integrated into enhanced tools continuously. Two terms to describe emerging practice merit some upfront clarification: vibe coding and agentic coding.
Vibe Coding
A neologism coined by Andrej Karpathy, vibe coding describes the development of software solely through text prompts, without manually editing source code. Karpathy’s original explanation captures the process well:
Tools like Bolt, Replit and Lovable support this development style, allowing users to generate visually appealing apps with minimal technical intervention.
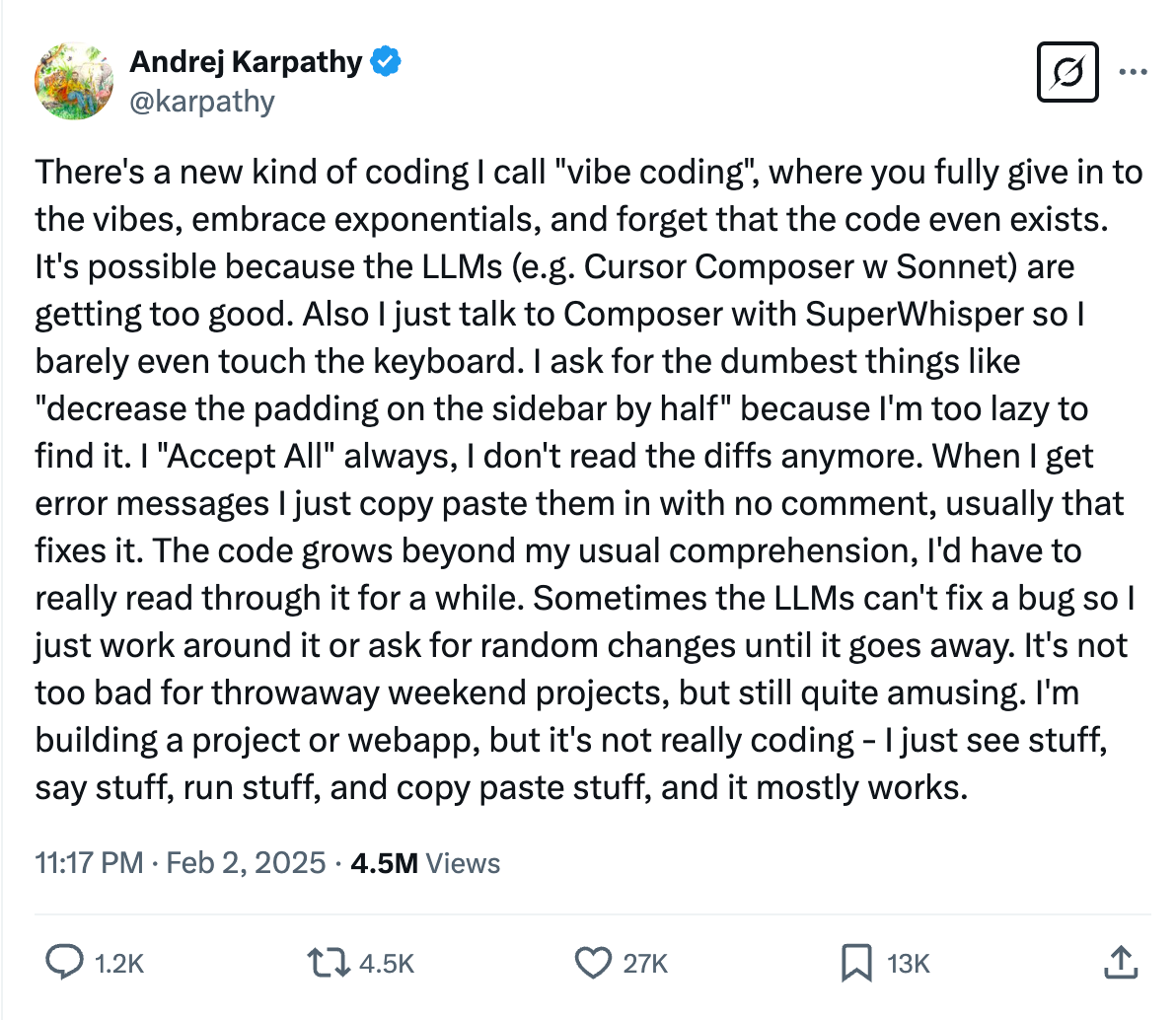
Here’s an example of a web app called Mapsearcher being developed in Lovable. The interactive chat window on the left shows how the application was seeded using a text prompt and some prior web code showing how to integrate a mapbox-gl widget:
While vibe coding is initially exciting and incredibly productive, it it is easy to get derailed when something breaks. If the person driving the session is a non-developer, lacking debugging experience, they will struggle to understand and fix the issues. Fixing errors often requires a traditional developer skill set.
Agentic Coding
Enter AI code editors where AI works alongside a developer within an IDE like Cursor or Windsurf. These tools offer a more controlled and powerful workflow for detailed work, ideal for more complex tasks. Editors can leverage LLMs like Claude Sonnet, DeepSeek, or Groq to act as intelligent pair programmers for a growing range of use cases. The AI code editors are increasingly migrating from interactive chat to interfaces where the AI can also execute shell commands and marshall a wide variety of tools to achieve their goals. This is referred to as agentic coding.
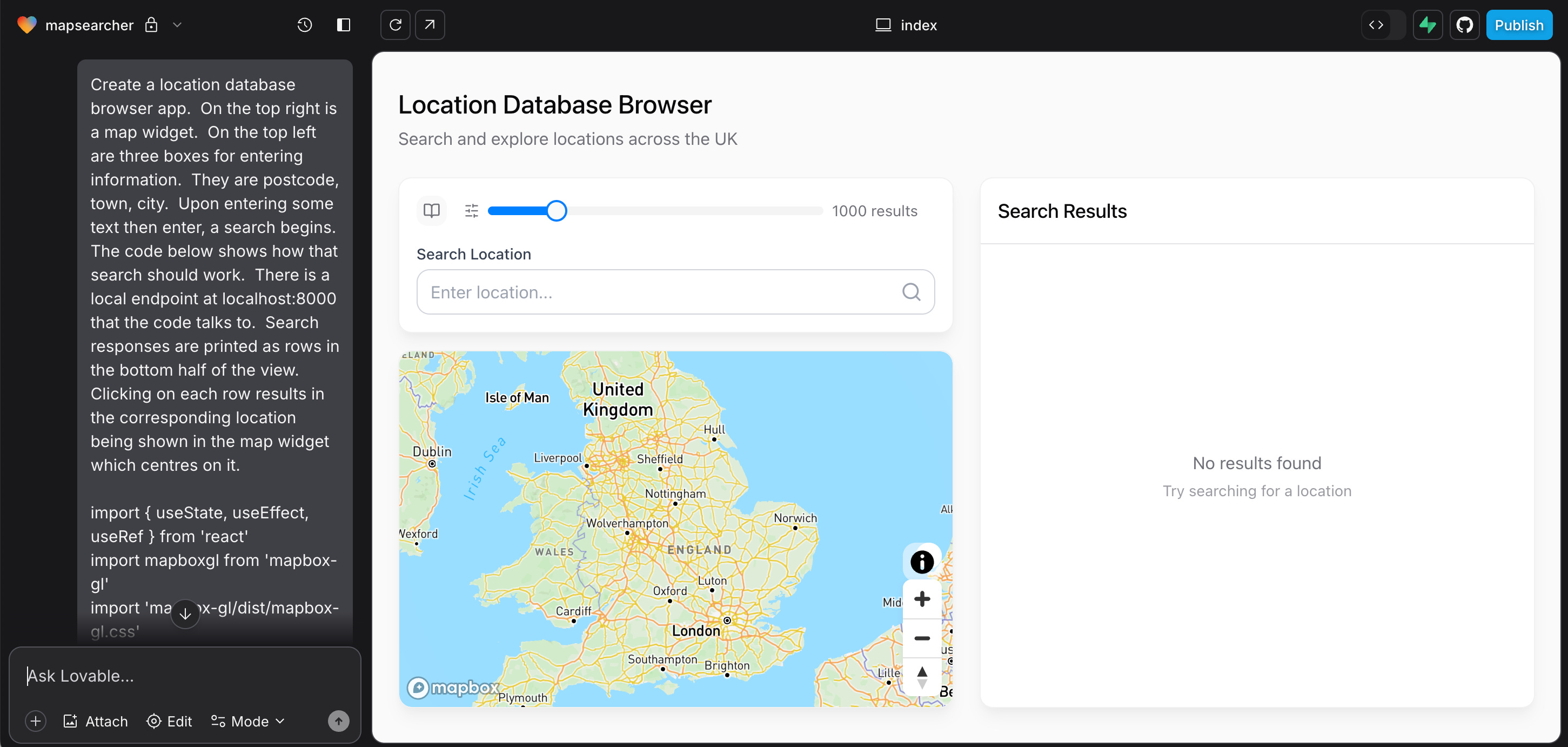
The screenshot below shows Cursor (which is a fork of Microsoft’s Visual Studio Code) highlighting code diffs suggested by the LLM on the right, together with editable source files on the left. Note we are running in Agent mode which involves interfacing with a variety of tools including ones we can import using a very promising new standard called MCP (Model Context Protocol):
Though often lumped together, vibe coding and agentic coding represent two distinct development modes. Which one you use depends on the nature of problem you are trying to solve and also on the experience of the individual using the tool.
Design-Led Approach (Vibe Coding)
In this mode, tools like Lovable are used to generate a working prototype of a user experience you may even have sketched out and passed in as an image with an initial prompt. Users generally avoid editing the code directly and make progress through prompting alone. The experience feels magical at first - fast, creative, and empowering. You accept direction from the tool and go with its flow. This approach is better suited for simple user-centric applications with standard UI flows. It doesn’t work well with complex workflows or application logic and is not the best approach for scenarios that require a lot of custom logic. The user relies on the AI and its vision, often without scrutinizing the resulting code. Based on experience working with Lovable, this approach only really works to establish a baseline you can use for a proof of concept.
Engineering-Led Approach (Agentic Coding)
Here, the developer partners with AI through an IDE like Cursor or Windsurf, issuing prompts and reviewing code diffs in real time. This method requires a baseline knowledge of software development. Cursor excels in this workflow and has become a favorite among developers who frequently use it in Agent mode.
An Engineering-led approach with human oversight is preferable when precise control, iteration, and debugging are required. Using the agent interface to choreograph various development activities including managing git commands speeds up development and testing.
My Combined Approach: ChatGPT + Cursor + Lovable
What works best for me is a hybrid method based on an coding agent team of three. I use ChatGPT for planning, Cursor for engineering, and Lovable for prototyping UI. Here’s my workflow:
Use ChatGPT to develop a specification and todo list for the backend and frontend of the system. You can input a visual sketch for the front end.
Feed the todo list for the backend into Cursor and work with it to develop working software for the backend including test code and Swagger API documentation.
Commit the backend + test code to a target Github directory.
Feed the API documentation and sketch of the frontend into Lovable to develop a v1 that integrates with the backend.
Refine the UI of this v1 version of the app in Lovable then sync from there to the same Github repository as the backend.
Continue all ongoing development, refinement and maintenance in Cursor.
Generate terraform to deploy software to target virtual machine.
I’ll walk through a couple of projects I have developed in the last few weeks that utilised this combined approach. Both of them were vibe coded - I did not write a single line of the software. Instead I used what I call fine prompting to develop and then adjust the software until it worked.
Mapsearcher
Mapsearcher is an example of a project I built that follows the combined approach outlined above using Cursor to develop and test the backend and then Lovable to build the initial UX. It’s a modern web application that is able to explore UK postcodes, districts and towns with spatial search capabilities.
Mapsearcher was built to provide a visual tool for aiding in understanding a dataset of some 2 million UK postcodes I obtained at work housed in a single csv file. I used Cursor to develop this script to convert the csv into a sqlite database. Once that was in place, I was able to build a Python-based FastAPI backend over it. The database uses SQLite and its open source SpatiaLite extension to provide spatial SQL capabilities. In addition, the app is fully dockerised with frontend and backend in two separate containers:
The frontend mapping UI is built with React and TypeScript. Mapsearcher provides the following functionality:
Spatial Search: Search locations within a specified radius of any point
Multi-mode Search: Search by postcode, town, or county
Interactive Map: Visual representation of search results with Mapbox integration
Geofencing: Display and filter results within a specified radius
Mock Data Support: Fallback to mock data when backend is unavailable
Modern UI: Built with React, TypeScript, and shadcn/ui
You can access the version of the app hosted on Lovable here. The screenshot below shows what it looks like locally with the backend running. Mock data is displayed when the app cannot find the backend which I am not able to run in the Lovable environment:
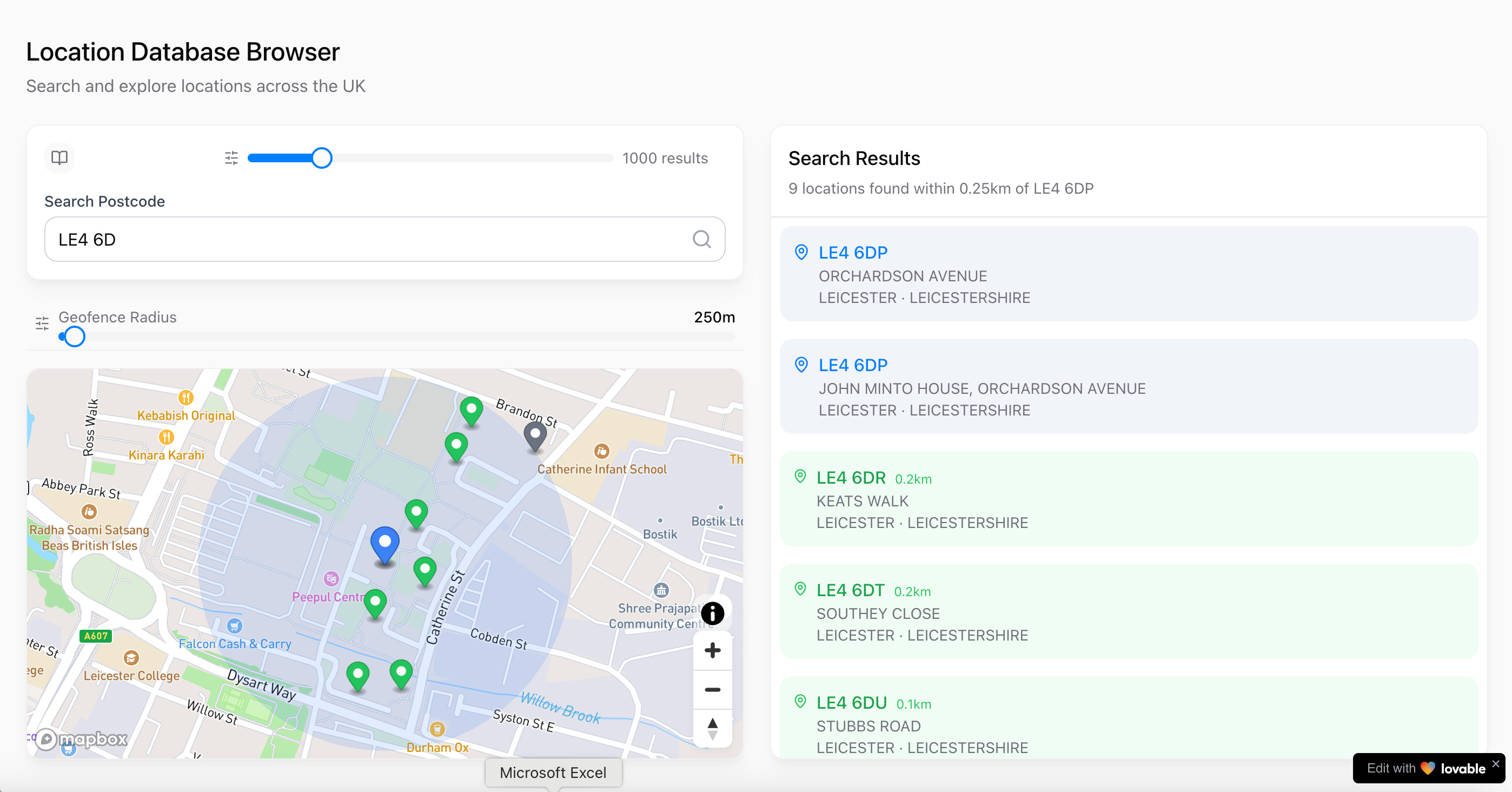
You can view the code generated by Lovable and Cursor in Github here. The total build time was about 3 days.
MNIST Neural Network Explorer
The MNIST (Modified National Institute of Standards and Technology) dataset, released in 1998, consists of 70,000 images of handwritten digits (0–9) of 28 x 28 (ie. 784) pixels. It has become a foundational benchmark for evaluating and comparing image classification and machine learning algorithms, especially in early neural network research so it’s a great starting point for understanding some basic concepts around neural nets. Here are some sample images of handwritten digits:

As part of some AI training I am providing for a client, I introduced the concepts involved in building a deep learning model that can recognize handwritten digits using the MNIST dataset. By way of recap, here's how that process works, step by step:
Designing the Network. Start by building a simple neural network. It takes in 784 inputs—one for each pixel in a 28×28 image in the MNIST dataset—and produces 10 outputs, one for each possible digit (0–9). In between, there’s a hidden layer made up of extra “neurons” that help the network learn more complex patterns. There’s no fixed rule for how big the hidden layer should be—this is more of an art than a science. A common choice is around 128 neurons, though other sizes like 64, 256, or more can also work well depending on the task and resources. All parts of the network are connected by weights, which tell the model how much influence each connection has on the final prediction.
Understanding the Input. Each image is turned into a list of 784 numbers, one for each pixel. These numbers show how dark each pixel is (not just 0s and 1s, but values from 0 to 255, often scaled between 0 and 1).
Training the Model. Show the model lots of example images along with the correctly labelled answers (e.g., "this is a 3"). The model makes a guess, and we check how far off it was. This difference is called the error.
Learning from Mistakes. The model uses a process called backpropagation to adjust its weights so it can make better guesses next time. Backpropagation is an algorithm used to train neural networks by calculating the error at the output and then adjusting the network's weights backward through the layers. The model learns by slowly improving with each example it sees.
Testing the Model. After training, we test the model on a different set of images it hasn’t seen before. This checks whether it has really learned to recognize digits, or if it just memorized the training examples.
Improving Over Time. Repeat this training and testing cycle many times, and with each pass (called an epoch), the model usually gets a little better until the errors are low enough.
This helpful explainer describes in greater detail what is going on inside the MNIST neural network. The process of building the model constitutes an algorithm. The model is the program that is generated by that algorithm. In other words, it is simply executable code that takes input of a similar form to what it was trained on and uses its network of trained weights to generate an output guess. As IBM put it:
An AI model is a program that has been trained on a set of data to recognize certain patterns or make certain decisions without further human intervention. Artificial intelligence models apply different algorithms to relevant data inputs to achieve the tasks, or output, they’ve been programmed for.
MNIST Neural Network Explorer is an app built with Lovable and Cursor with three views. The first allows the user to explore the MNIST data set. The second takes them through the process of building a model for handwritten digit recognition. The third view permits the user to test the model they have built including testing a digit drawn with your finger or mouse. There are limitations. I’ve noticed that while the web code is billed as responsive, the app doesn’t render well on a mobile phone.
The app is accessible on Lovable here. The screenshot below is from it running on a laptop showing the second training view with its visualisation of the neural network’s input layer, output layer and one hidden layer:
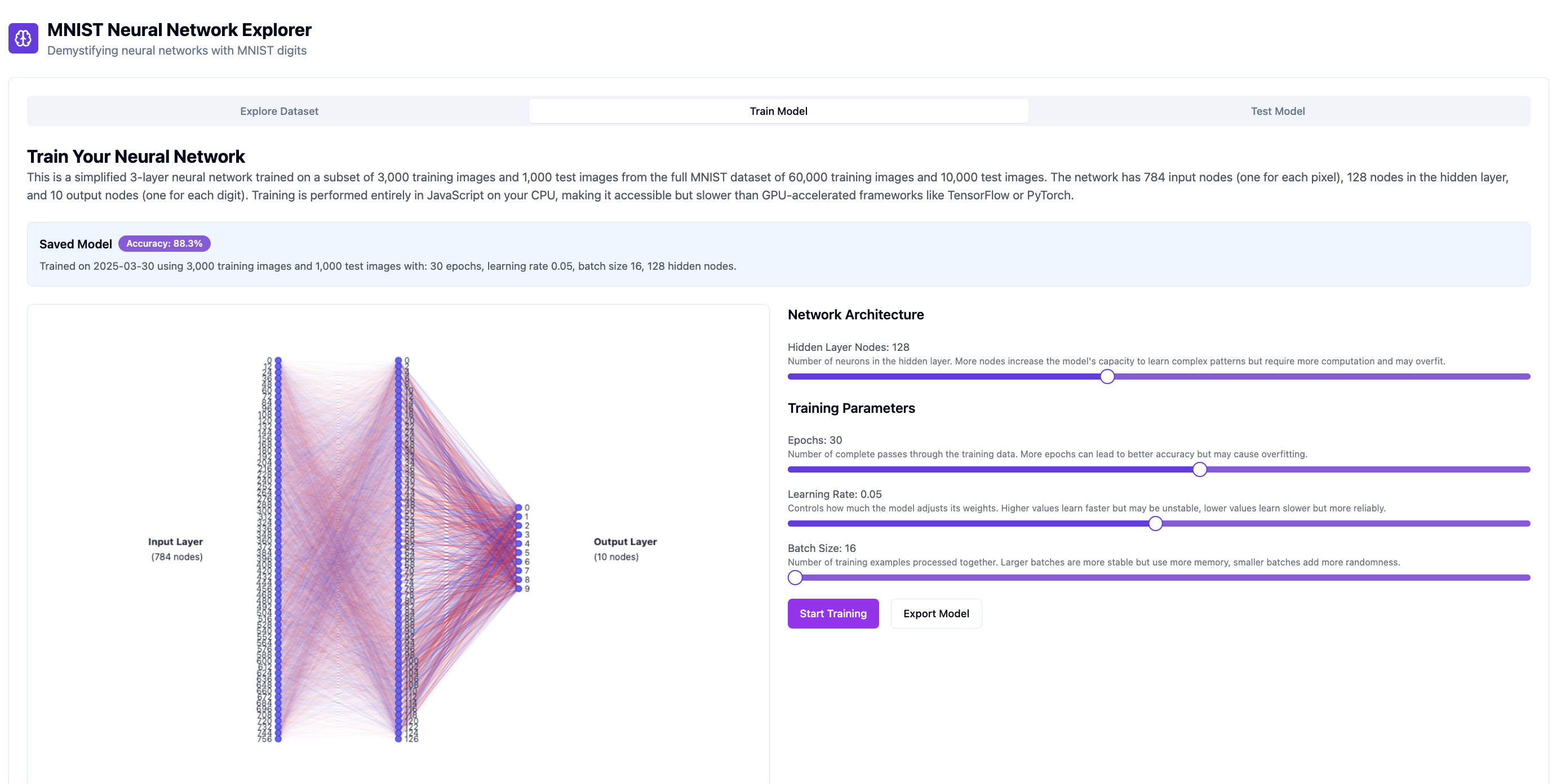
You can view the code generated by Lovable and Cursor in Github here. Total build time was 1 day.
Reflections on the Future
Working with tools like Lovable and Cursor has demonstrated to me that the development of high-quality, attractive web software can now be significantly aided by prompt-driven workflows. It’s provided a glimpse into a new era where the programming language for software development is English and software development is increasingly about describing what you want, not writing every line of code. That could usher in lots more code creativity as software development to become accessible to millions more non-technical people.
However, readers of this publication know that I cleave to a pessimistic vision of how AI advances will play out for humanity. There’s a darker side to coding AIs too.
These tools are improving rapidly and could reshape the entire software industry. The combined approach I outlined earlier could be obsolete a few months hence and replaced with vastly more powerful techniques. Instead of engineers writing code, we may soon see vast networks of specialized AI agents collaborating to build software under human supervision. Many existing tech jobs could be lost in the process. Steve Yegge paints a dramatic picture of the world to come colliding with us in less than a year:
Agents are coming. Vast fleets of them. Not just coding agents. Agents are arising everywhere, across entire businesses and production tech processes.
If you’re looking for a call to action, then I give the same advice to both humans and companies: Switch to chat. Ditch completions. Stop writing code by hand. Learn how validation and verification work in the new world. Familiarize yourself with the space, and follow the state of the art. Stop whinging and turn this into an engineering exercise. Stay on top of it. You can do it.
The new job of “software engineer,” by the end of this year, will involve little direct coding, and a lot of agent babysitting. The sooner you get on board with that, the easier your life will be.
The software engineer of the near future may not be doing any manual coding at all, just orchestrating agent workflows and verifying their output. The transition will be swift and disorienting for many.
Anyone who's spent years honing their coding skills and writing code is likely to feel ontological shock as it happened. And this is only the beginning. These tools are, today, the worst they'll ever be. From here, they’ll only get more capable. AI improvements will continue until the process for developing many categories of software is largely automated.
For the last thirty years or so, we lived though a period when the software developer were seen as exceptional. In truth, the status of the software developer is no different from that of ordinary human beings. There is nothing exceptional about either. Both are unravelling under the weight of accelerating automation. Code and cognition alike seem equally susceptible to machinic reduction. For a growing number of use cases it feels as if there is nothing sacred about either after all and that ultimately, text really is all you need.