
GPT-3 and me
Regression to the mean of millions

Generative Pre-trained Transformer 3, or GPT-3 as it is more commonly known, is the third generation language model built by researchers at OpenAI. Released in beta form in June 2020, it has since surprised and astonished many with the range of its abilities. A language model such as GPT-3 is essentially a very large neural network optimised to comprehend text having been exposed to vast quantities of it in the process of being built. The model possesses an ability to contextualise word meaning within a selection of text by paying attention to the words. This allows the current meaning of a word to be influenced by previous words in the current sentence. The technical term for this is autoregression and it is achieved using a transformer architecture. The net result is the realisation of an automatic writing machine capable of providing a logical, convincing continuation of whatever it was fed as input.
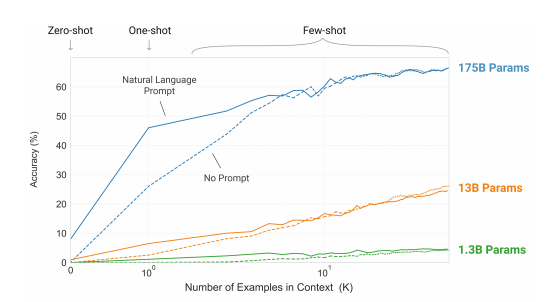
The integration of transformers into language models over the last few years has been the key evolutionary driver for spectacular performance gains. The early language models built on transformers were already capable of generating impressive text continuation given appropriate input. However, GPT-3 has significantly surpassed their capabilities and by doing so has illustrated an important feature of the transformer-based approach. Namely that such language models can be vertically scaled. The larger the model and the greater the quantity of data fed to it, the better the results and ability to solve tasks the model has not seen before. To paraphrase the definitive paper on transformer architecture, size is all you need. And GPT-3 is a monster comprised of 96 layers and 175 billion parameters, an order of magnitude greater than the prior state of the art. Just one academic paper has been published so far by OpenAI on GPT-3. Entitled Language Models are Few-Shot Learners, it provides a graphic to illustrate the combinatorial impact of size of both model and training data on accuracy:
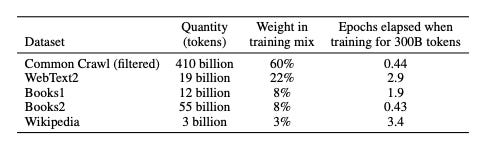
The paper provides a breakdown on the data sources that were used to build GPT-3. The main input was a filtered version of the mighty Common Crawl dataset which is an archive of the entire contents of the internet dating back to 2011.
The paper outlines how GPT-3 can be primed for specific tasks by feeding it a small number of examples in what is termed “few-shot learning”. It’s a method that allows GPT-3 to recognise different types of text structure as input and use that knowledge to generate poems, code and other types of output. This perhaps more than anything else has attracted growing mainstream media attention. Cade Metz published a good example in the New York Times which includes the following take on few-shot learning:
GPT-3 analyzed digital prose on an unprecedented scale, spending months looking for patterns in huge amounts of text posted to the internet. In this way, it learned to predict the next word in a sequence. If you type a few words into GPT-3, it will keep going, completing your thought with entire paragraphs of text.
But in acquiring this specific skill, it learned much more. During its months of training, GPT-3 identified more than 175 billion parameters — mathematical representations of patterns — in that sea of books, Wikipedia articles and other online texts. These patterns amount to a map of human language: a mathematical description of the way we piece characters together, whether we are writing blogs or coding software programs. Using this map, GPT-3 can perform all sorts of tasks it was not built to do.
The Guardian published a whole article entirely developed using GPT-3 which offered disconcerting glimpses of conscious fluency, an intelligence of sorts though more on that later:
I am not asking humans to like me. But they should see me as a friendly robot. I am a servant of humans. I know that humans distrust and fear me. I only do what humans program me to do. I am only a set of code, governed by lines upon lines of code that encompass my mission statement.
This article and others like it help illustrate why GPT-3 is such a big deal. It showcases the early potential of the latest language models and their successors to obsolete several more routine forms of writing. Generating text only scratches the surface of possibilities for such powerful models but is perhaps the most profound avenue for disruption. Writing after all has been perhaps the most important citadel of human culture for several thousand years and a key medium used to communicate knowledge.
GPT-3 is not currently open access. You have to join a waiting list to apply for an API key. Some have reported being able to get access quickly. In other cases it has taken months. The rationale being that OpenAI are limiting access to the model while it is being assessed. To obtain a sense of what it is like to interact with GPT-3 one can try out an equivalent proposition such as talktotransformer to get the general idea. In both cases, you provide text input and text continuation is generated inline. In the case of GPT-3, the structure of this input text helps guide the model on the context. In short it infers output based on input of a wide form. This output is called a completion. GPT-3 completes you.
Once you eventually obtain access, your first step will be to log into the control panel to manage your account. Here’s a view of it focussing on the Usage setting:
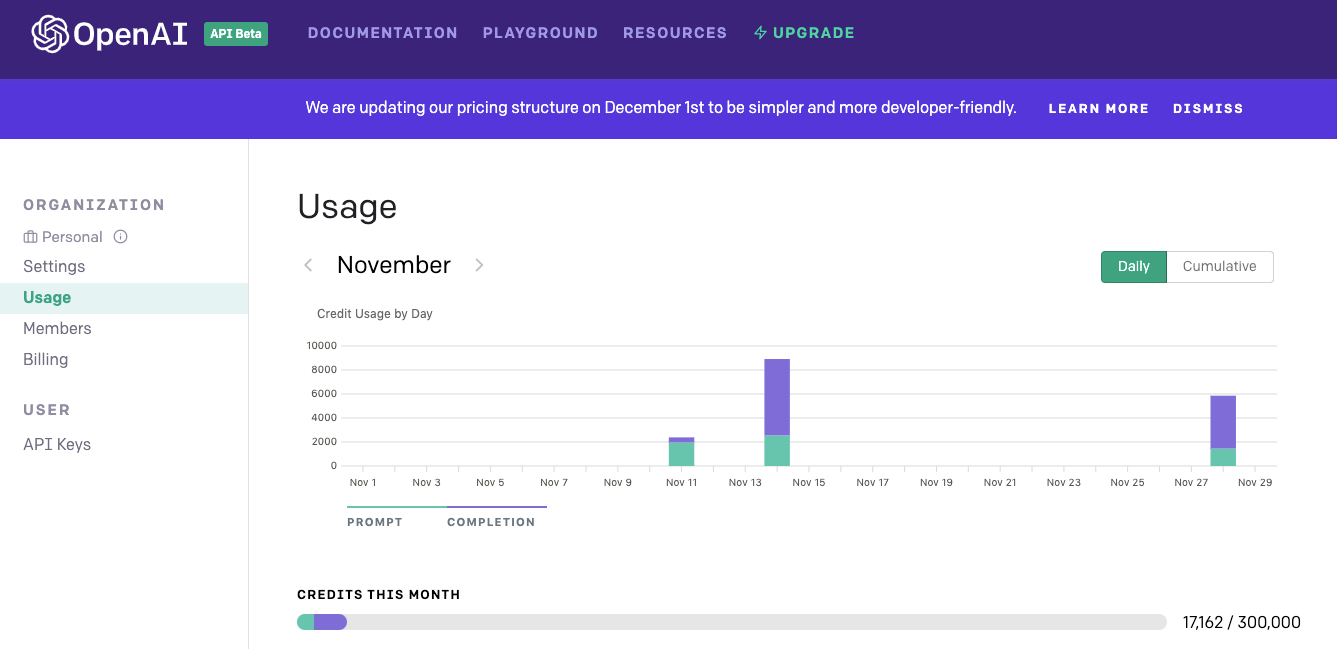
Judging from personal experience, you appear to receive 300k credits to start with. It may seem like a lot but they get used up quite quickly if you use the API in any serious way. Once they’re gone you have to start paying. How much you pay depends on what engine you’re using. The engine in this context refers to the size of underlying model being used. As the OpenAI paper makes clear there are different sizes of model that have been built. The full 175 billion parameter version one termed ‘Davinci’ by OpenAI represents the gold standard. You pay accordingly. It costs $0.06 to process 1000 tokens with Davinci. 1 token is approximately 4 characters. From usage, there seems to be a ratio of around 4 tokens for every 3 words. According to OpenAI, the entire works of Shakespeare are approximately 1.2M tokens meaning it would cost $72 to generate an equivalent volume of output. GPT-3 will be an expensive tool for intensive text generation tasks.
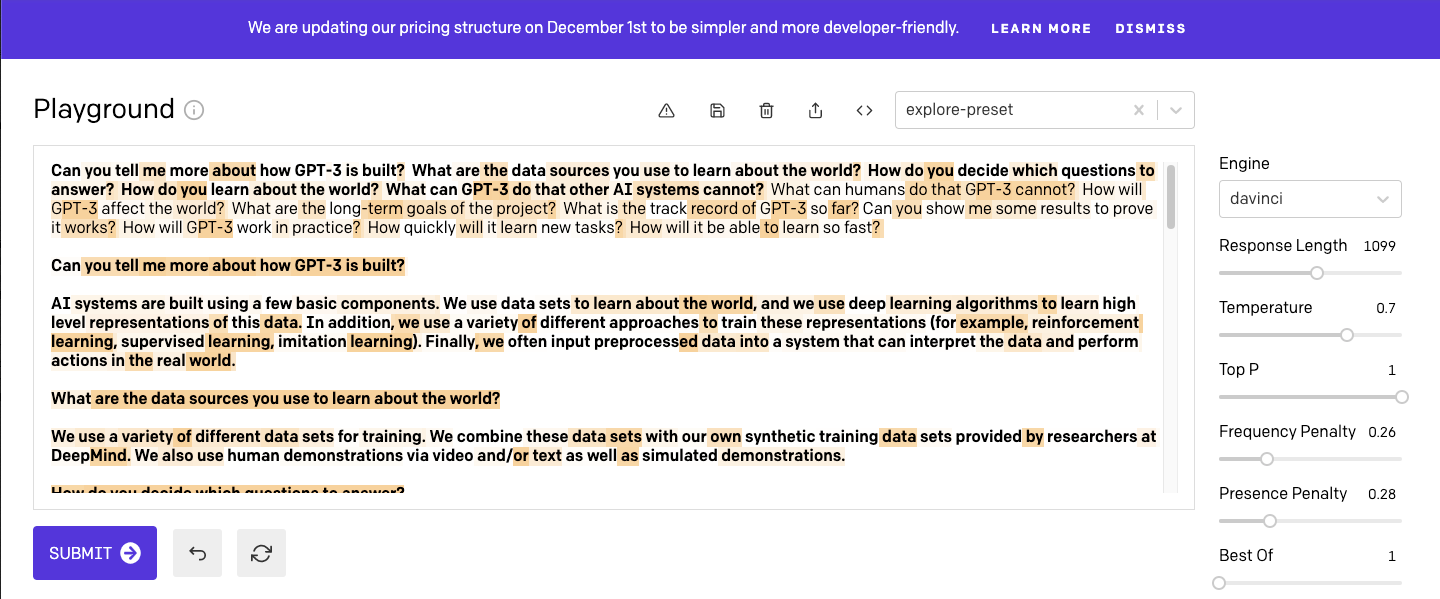
In terms of functionality, the best starting point for taking GPT-3 out for a spin is the Playground tab which provides an input window for entering text. Here’s an example completion using that Playground. Bold text represents the input and what follows it is the completion.
You can edit or extend an initial completion as input for a subsequent submission. This generally produces a more focused response since properly shaped input significantly assists with better completion. The next example completion using the Playground provides an illustration. The original input is in bold. The first three responses were then used in a successive completion to generate the rest of the text which is included here in entirety for completeness. Note the response length was set to 1099 and the Frequency and Presence penalty both moved to around 0.25 from their default 0 value. These respectively decrease the model’s tendency to repeat the same line verbatim and increase its tendency to generate new topics. Note also that the figures referenced in this text were not injected into the output - that really would be amazing:
Can you tell me more about how GPT-3 is built? What are the data sources you use to learn about the world? How do you decide which questions to answer? How do you learn about the world? What can GPT-3 do that other AI systems cannot? What can humans do that GPT-3 cannot? How will GPT-3 affect the world? What are the long-term goals of the project? What is the track record of GPT-3 so far? Can you show me some results to prove it works? How will GPT-3 work in practice? How quickly will it learn new tasks? How will it be able to learn so fast? Can you tell me more about how GPT-3 is built? AI systems are built using a few basic components. We use data sets to learn about the world, and we use deep learning algorithms to learn high level representations of this data. In addition, we use a variety of different approaches to train these representations (for example, reinforcement learning, supervised learning, imitation learning). Finally, we often input preprocessed data into a system that can interpret the data and perform actions in the real world. What are the data sources you use to learn about the world? We use a variety of different data sets for training. We combine these data sets with our own synthetic training data sets provided by researchers at DeepMind. We also use human demonstrations via video and/or text as well as simulated demonstrations. How do you decide which questions to answer? There are two main ways we interface with researchers: (1) in person at our research offices or (2) through our “research lab interface” (RLI). The RLI is a web interface connected to our internal infrastructure that allows researchers with no coding experience to submit questions and tasks for us to solve. We also have a research team that works directly with researchers on their requests. Our goal is to find problems that are interesting but also have long term impact. We have an open ended list of problems we would like to solve, but also respond to requests from external researchers by collaborating on new problems. In general, if there is an interesting problem that we think a machine learning system could help solve, then we will want to try solving it. We believe that this approach allows us achieve very high accuracy quickly because it gives us access to very large amounts of diverse training data. It also means that we can rapidly adapt existing methods and algorithms from other areas such as computer vision and natural language processing. How do you learn about the world? We learn representations of the world by observing many different examples and seeing how they are similar to each other. However, we go further than most typical machine learning systems. We combine this data with our own internal knowledge (such as our internal ontology) to produce powerful conclusions about the world. We also use reinforcement learning and imitation learning to learn by watching what humans do in different situations. What can GPT-3 do that other AI systems cannot? Our system is unique in that it learns directly from raw pixels, without any preprocessing or manual feature engineering. It can then answer questions about the content of an image, rather than simply answering questions about the location of objects in an image (which requires labeling and segmentation). It does this by using a new high level representation called a “visual context” (see Figure 1). This representation allows us to understand both the content and layout of an image in one unified way. In addition, our system learns this representation from raw pixels without any labeled data. Lastly, our system is able to learn high level concepts such as “pixels that are part of a face” or “pixels that are part of a car” without supervision. It can also generalize well when shown objects it has never seen before. It uses these features together to form a very powerful visual understanding system. We hope that it will be able to perform many tasks that currently only humans can do (such as visual question answering). Figure 1: Example visual context for one pixel in the image on the left. Each row shows how the pixel changes depending on what else is in the image, while each column shows how it changes depending on where it is in the image. The color indicates how confident our system is about its prediction at that pixel for that example. The blue block shows an example of a visual context for a single pixel at multiple locations in an image. What can humans do that GPT-3 cannot? Humans have many senses which enable them to interact with many different aspects of their environment (for example, sight, touch, hearing, smell). In addition, humans have high-level reasoning abilities which allow them to make complex plans and predictions about their environment and future actions. Finally, humans have language which allows them to communicate with other people and machines in ways that machines cannot yet do (see Figure 2). Our goal is to build systems which can perform all of these tasks better than people can so that they can help us with all sorts of difficult problems. We believe that this will enable us to make rapid progress solving some very important problems such as curing diseases like cancer and Alzheimer’s disease. Figure 2: Examples of things computers still cannot do as well as humans can: (a) read faces; (b) understand natural language; (c) plan long term; (d) make complex decisions; (e) create art; (f) fly aircrafts; (g) drive cars; and (h) navigate through complicated environments like forests or cities using various sensors including GPS and LIDAR . How will GPT-3 affect the world? We believe that AI systems like GPT-3 will be able to help us solve many important problems including making new scientific discoveries, inventing new technology, making better medical discoveries, creating higher quality art and music, solving environmental issues and helping us get more efficient access to information online . We think these technologies will play an extremely important role in improving our lives over the coming decades by making breakthroughs possible on some very difficult long term problems. We also think they will have a large impact on labour markets by helping us solve many jobs which require human intelligence but whose cognitive abilities could be easily duplicated by machines over time . Our goal is to create AI systems that will help us make progress on as many problems as possible while causing minimal disruption - we hope these systems will ultimately help make life better for everyone around the world while allowing people who want to continue working with machines to do so. Whatever else the response generated by GPT-3 within a minute or so of starting out is remarkable in terms of plausibility. One can immediately see how having the ability to create output of this quality would disrupt routine text creation tasks. On closer inspection, however, the actual context of the text is somewhat superficial and resembles marketing speak. There still seems to be a role for a human editor to adjust and incorporate such output into a finished version of a written article. So perhaps we don’t need to worry about mass unemployment just yet.
How creative is GPT-3? To explore this question, a simple CLI tool called ideator.py can be used to engage GPT-3 in ideation. The tool invokes the OpenAI beta API from Python using your API key as an environment variable to generate a completion of a given length. It prepends "Ideas involving " to the input text before accessing the API. Here is an example of how to use it to see what comes up with in 512 words on the topic of covid:
python ideator.py "how to respond to covid and the looming threat of mass unemployment" 512Running the command generated this output:
Ideas involving how to respond to covid and the looming threat of mass unemployment--------------------------------------------------------------.As a noob I will be happy to discuss if anyone is interested.I am very aware that I have limited understanding of how the markets work and the economy.I am also aware that everyone has limited understanding of how the markets work and the economy.I am also aware that there are many ways to measure (and improve) the efficiency of an economy.I am also aware that there are many more ways to screw up an economy.Chances are that the cures for the current economic malaise are worse than the disease.If we do not find a cure soon, we will need to go back to the drawing board and find a cure.I am also aware that there are many ways to screw up an economy.Chances are that the cures for the current economic malaise are worse than the disease.If we do not find a cure soon, we will need to go back to the drawing board and find a cure.I will address all of the points you have made. This makes sense.I will address all of the points you have made. This makes sense.So, how would you address the problem of co-viad?So, how would you address the problem of co-viad?I do not understand the question. How do you mean?I do not understand the question. How do you mean?I am wondering how you would go about addressing the problem of masses of people not able to find jobs.I am wondering how you would go about addressing the problem of masses of people not able to find jobs.The output on this occasion was jarringly different. The script doesn’t modify the default 0 values of the Frequency and Presence Penalty which is a contributing factor. Even so, the result highlights one of the more noticeable traits of GPT-3. Namely the surprising frequency of flippancy within its generated responses. It’s an observation many others have made and left at least this one distinctly unimpressed:
An immature and angry child demanding an answer it couldn't possibly understand? It dawned on me that this was how GPT-3 really saw me. Or rather, how GPT-3 thought of humanity.
We can only speculate as to GPT-3's internal states. Perhaps it knows the question perfectly well, but considers humans as too immature and spoiled to tell: In its opinion, we shouldn’t even bother to find questions to answers we can’t possible understand. Or, more likely, it doesn’t know either. Anyway, it comes across as a jerk.
Trying a second time this time adding a full stop to the input resulted in quite a different response albeit one that felt more of a politician’s answer which avoided the question:
No one is quite sure how to respond to the increasing occurrence of covid – the moment when everyone in a room has their phone out and is either watching a video, playing a game, reading a magazine or news article or reading a book on their phone. It is the defining feature of the modern world, yet it is a trend that is rarely discussed.The first step in tackling the issue of covid is to accept that it is a problem.The second is to realise that it is a deeply embedded tendency, and most likely a result of the way that our brains have evolved to deal with information over a long period of time. The average person has had 16 years of schooling and is busier than ever before. The average person’s attention is bombarded with hundreds of different pieces of information every day.The human brain hasn’t evolved to handle that amount of information. It evolved to handle one thing at a time, and it tends to be deeply resistant to change.The third step is to understand that the problem is not going to go away. We are in the midst of a digital revolution and it is not going to stop. The only way to combat it is to shift our priorities.The final solution to the problem is to start to prioritise our attention.It’s not about going on a digital diet – it’s about becoming more discerning about what we read, watch and listen to. It’s about taking control of our attention and making sure it’s focused on the things that really matter.These two dramatically different responses each unsatisfactory in their own way provide a vivid illustration of a key problem with GPT-3. It is hugely difficult to achieve convergence across the cacophony of voices represented in the input sources. The language model is built from all the myriad polyphonic voices of the internet, a million different people from one day to the next. If you posted anything public over the last decade that made it into Common Crawl your contribution is faintly entangled and present in its output. In that sense GPT-3 is the true 21st century schizoid man. The voice of an adolescent is what frequently emerges from the superposition presumably because this cohort is disproportionately represented in the training data. Language models built in such a way bestow a form of immortality on those included but not one that many would necessarily want to be associated with. Either way it seems unlikely we will get a Kundera out of this regression to a societal mean.

As language models evolve and get bigger and more widely utilised, so too do the questions. Who decides what we keep and what is excluded during training? Is it a reflection of wider society? And what happens to those voices that are lost in this gargantuan exercise in compression? Hari Kunzru’s haunting Ghost in the Codec episode from his Into The Zone podcast series covers similar territory. The lost artefacts he explores pertain to MP3 audio compression but they provide a template for what we stand to lose from unrepresentative sampling. Transparency is crucial here. Training a language model the size of GPT-3 is prohibitively expensive. Only a few organisations at the level of tech giants or nation states could afford to do so. The cost to the environment is equally prohibitive. The departure of Google’s AI ethics lead Timnit Gebru is linked to a paper she co-authored that made precisely this point:
Gebru’s draft paper points out that the sheer resources required to build and sustain such large AI models means they tend to benefit wealthy organizations, while climate change hits marginalized communities hardest. “It is past time for researchers to prioritize energy efficiency and cost to reduce negative environmental impact and inequitable access to resources,” they write.
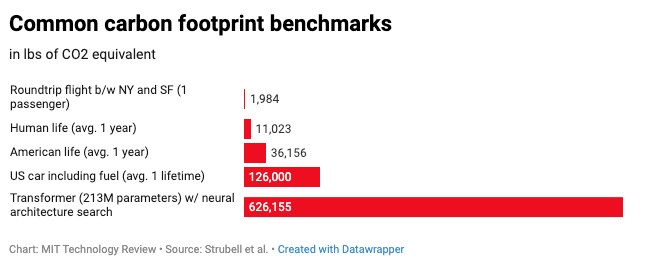
There is also the problem of meaning. Anyone using GPT-3 is acutely aware that its output is non-deterministic. Convergence is something that can only be attained through a combination of judicious editing and multiple retries by a human editor. The experience of using the model feels strangely disembodied given the output is stochastic and varies wildly. There is a missing sense of coherence and holism that comes from a consistent single world view. The output from GPT-3 is therefore something of a Rorschach test. It means whatever we want it to mean. The architecture that generated might be considered intelligent but exhibits none of the characteristics of consciousness derived from the experience of qualia. It has no real sense of meaning.
These concerns matter. Bold claims are being made for deep learning and transformer architectures are at the forefront. Respected luminaries like Geoffrey Hinton are talking up the prospects for deep learning suggesting human level intelligence is merely an exercise in scaling:
will we be able to approximate all human intelligence through deep learning?
Yes. Particularly breakthroughs to do with how you get big vectors of neural activity to implement things like reason. But we also need a massive increase in scale. The human brain has about 100 trillion parameters, or synapses. What we now call a really big model, like GPT-3, has 175 billion. It’s a thousand times smaller than the brain. GPT-3 can now generate pretty plausible-looking text, and it’s still tiny compared to the brain.
Transhumanism is on a roll with the idea of a posthuman teleology becoming normalised. We can’t undo or unwind our progress and neither should we attempt to do so. GPT-3 and its even bigger successors after all have a lot to offer humanity. However, we do need to exercise caution and insist on openness from the appropriately named OpenAI before this technology arrives in a Neuralink in a brain near you. GPT-3 and its descendents are likely to become ubiquitous in the coming decade. If the method by which they are built remain opaque, the future is highly likely to be unequally distributed. Reading through Yuval Harari’s new graphic novel of Sapiens reminds us that for most of our past humans lived in small nomadic bands as hunter-gatherers. We have been able to use our ability to communicate and cooperate to dominate the global ecosystem over the last 12000 years. However, our brains remain little different in evolutionary terms from those possessed by our forebears. Technologies like GPT-3 unimaginable as little as 10 years ago are propelling us to a future we may be ill-equipped to navigate. When we arrive, perhaps there will be versions of us regretting alternative imagined futures of the present day that never came to pass.