
AI art
Re. Diffusion and DALL-E

We are living in the golden age of AI art according to a recent article in the FT. Remarkable advances in applied machine learning in the last couple of years have enabled non-artists to conjure complex images solely from natural language text prompts to a generator. These generators, readily accessible through a web interface, provide a convenience layer over gargantuan AI models built by scanning vast corpuses of existing images and their corresponding descriptions. Using textual input to drive image creation allows for entirely new concepts to be imagined. The FT article discusses an example relating to a giraffe doing yoga which we will use as a convenient assistant for this post. Asking OpenAI’s DALL-E 2 to generate an image from the prompt “a giraffe doing yoga on the savannah in the style of van Gogh” yields the following image in about 9 seconds:

The ability to generate results as impressive as this in close to real time has ensured mass interest and a large number of AI art generators have been rapidly constructed to address demand. Each has its niche and its pros and cons. This recent survey of the state of the current art looks at what it considers to be the ten best ones. Their value proposition is clear enough. As Abhay Agarwal of Poly, a “DALL-E for design assets” company memorably put it:
99.9% of people in this world cannot create a convincing illustration, even given an infinite amount of time
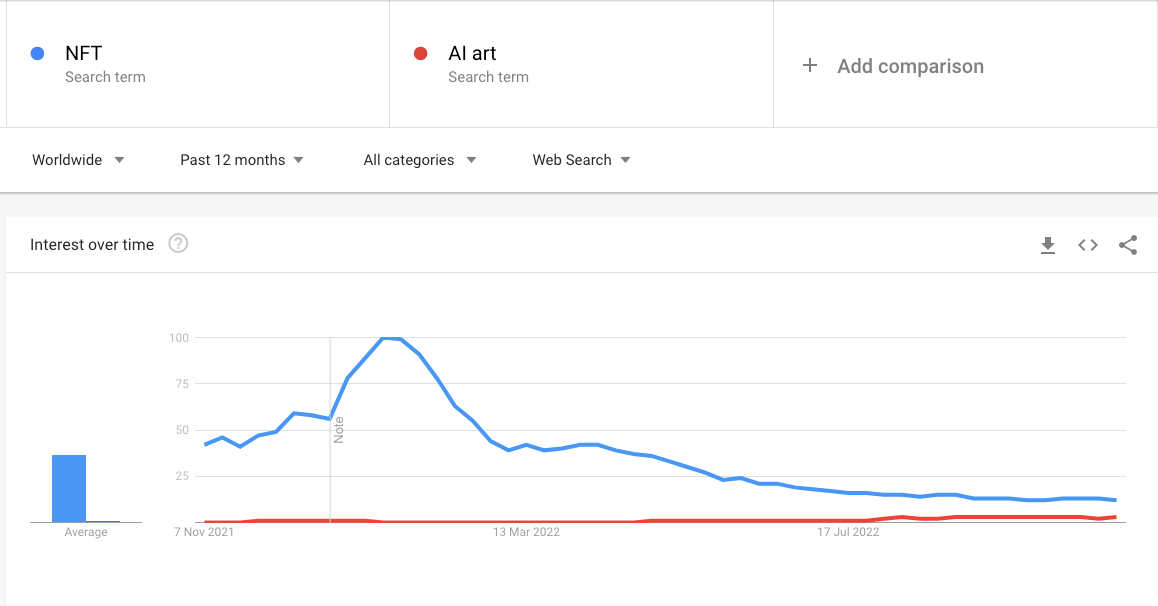
Google Trends reveals the level of interest in AI art has grown over the last year while it has declined sharply in NFTs. Unsurprisingly a lot of investor money has flooded into the space anticipating that these image generators will overtake NFTs as the next big disruption in the art world:
Some of the generators such as starryai have attempted to combine AI art with NFTs to allow both platform and artist to monetise the value created through this new art form.

Arguably the three best known AI art platforms are DALL-E 2, Stable Diffusion and Midjourney. The FT article cited at the top of this post distinguishes between their capabilities as follows:
Dall-E 2, whose name is a portmanteau of Pixar’s WALL-E robot and the artist Salvador Dalí, has one million active users and is generally thought to excel at realistic images and photographs. Midjourney has a more abstract, artistic style that users have found particularly good for making fantasy-, sci-fi- and horror-themed images. An open-source alternative called Stable Diffusion is one of the most popular among designers and artists; there is also Craiyon, a free public tool with a lower-quality output largely used for making memes.
Does AI art really live up to the hype? And how accessible are these services to users with no expertise or budget? Let’s examine the reality using DALL-E 2, Stable Diffusion and Midjourney as our references.
You can certainly produce arresting images with little effort with all three of these propositions. However, your mileage on the results may vary considerably between platform. The quality of the output is highly dependent on the skilful construction of the prompt input you use. In particular prompts need to work in a way that best fits the underlying large language model (or LLM) used. This will depend on the way that model gathered description information for the images it processed. Various research papers offer a deeper dive into the mechanisms involved such as this one from Cornell University entitled Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. Prompting was originally popularised as the route for fabricating text completions from LLMs. The approach achieved spookily impressive text completion results with GPT-3. Examples were provided in a previous post entitled GPT-3 and Me which also introduced a Python command line script developed to help generate completions on text prompts to encourage ideation. In the case of AI art, the same approach is used to generate images from the input text rather than generate text completions.
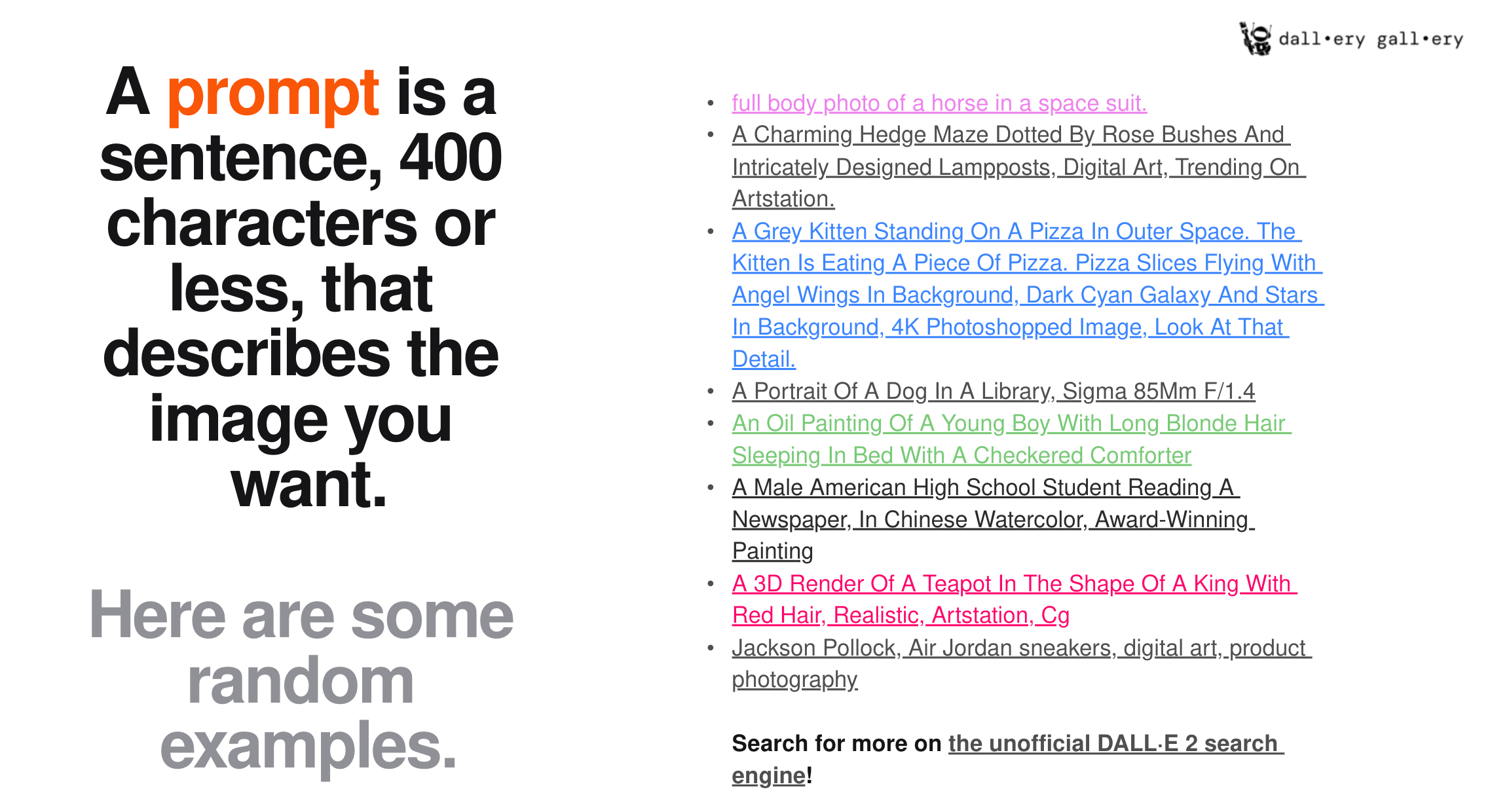
The consequence of the leaky abstraction introduced through the need for finely tuned prompts is the advent of what is widely termed prompt engineering. Numerous sites offering newcomers guidance on how to obtain the best results have sprung up. The 82-page DALL-E 2 prompt book is a good example which offers this explanation:
There’s even a prompt marketplace called promptbase where you can search, buy and sell prompts:
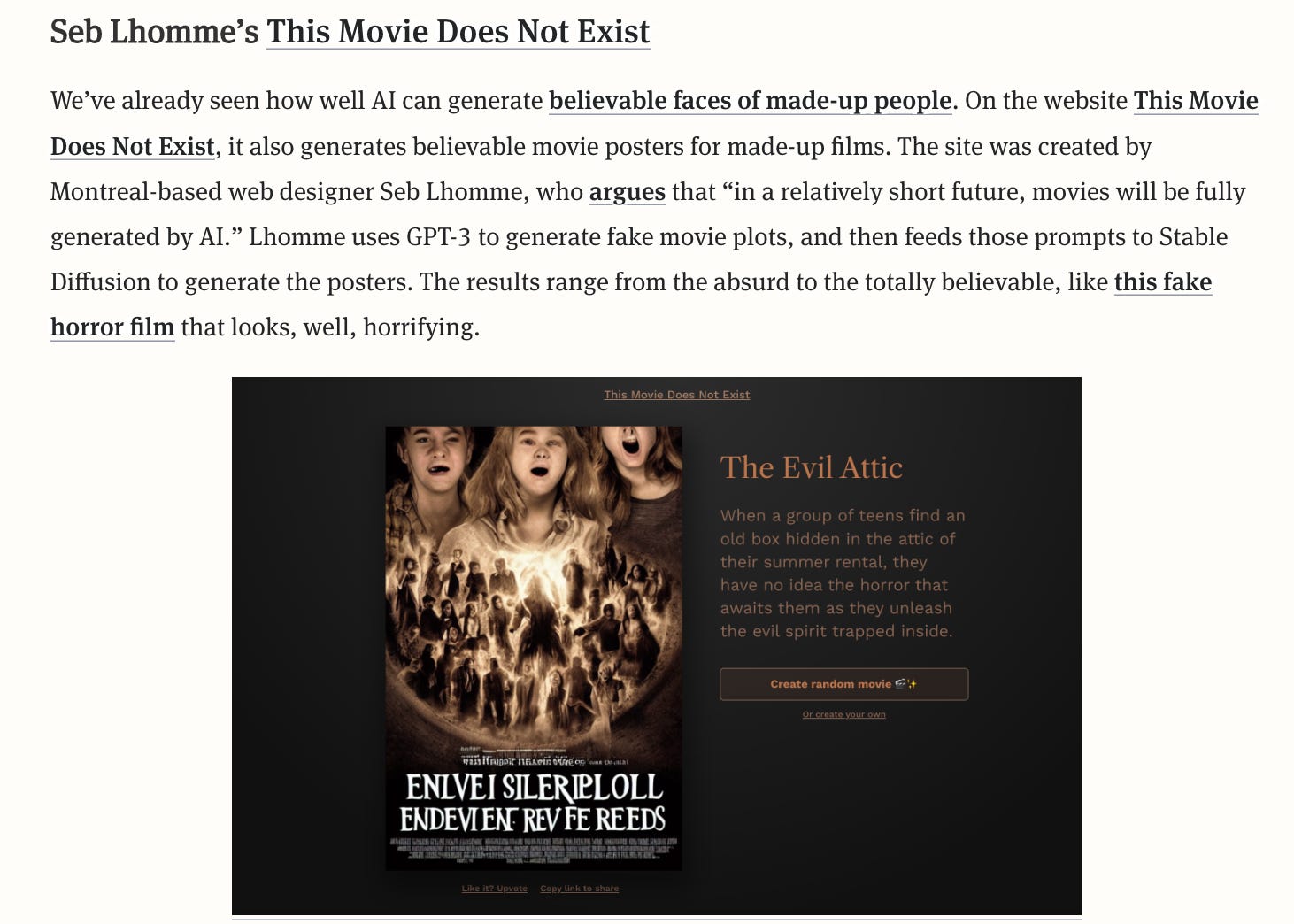
Inevitably a cadre of AI influencers has emerged with large followings. The Information surveyed fourteen of them including Seb Lhomme responsible for creating This Movie Does Not Exist, a site that creates plausible posters for imaginary films:
Two of the three highlighted platforms, Stable Diffusion and DALL-E, are now accessible programmatically through an API. This is a big deal as it allows developers to build tools and SaaS platforms that integrate their functionality. Most of these propositions use Stable Diffusion since the DALL-E API has only just been released at the time of writing. One such example of a SaaS platform is PhotoRoom aimed at Product Marketing use cases:

Over time we can expect these tools and dependent platforms to increase in sophistication. To understand why such a future will emerge, it is instructive to look at what has happened with GPT-3 over the last couple of years since the GPT-3 and Me post was written. In the intervening period a significant amount of new GPT-3 functionality has been added supporting a whole array of new use cases for text generation including coding and summarisation. Billing is now available through an easy to use PAYG model with a cap that can be set by the user. This is bound to encourage further adoption as it lowers the barrier to participation. It also enables powerful new automation possibilities as described in a recent tweet. The bold claim made here is that prompt-driven input yields better results than using Stack Overflow:


DALL-E is particularly interesting to watch in this respect since the OpenAI API it uses sits under the same authentication model used to access GPT-3. A Jupyter notebook outlining how to configure and use DALL-E 2 to generate AI art from first principles using Python has been published here. It illustrates an important aspect of using LLMs to generate either images or text, namely that results are non-deterministic. The giraffe generated by this snippet is not the same as the earlier one generated by DALL-E 2 using the same prompt:
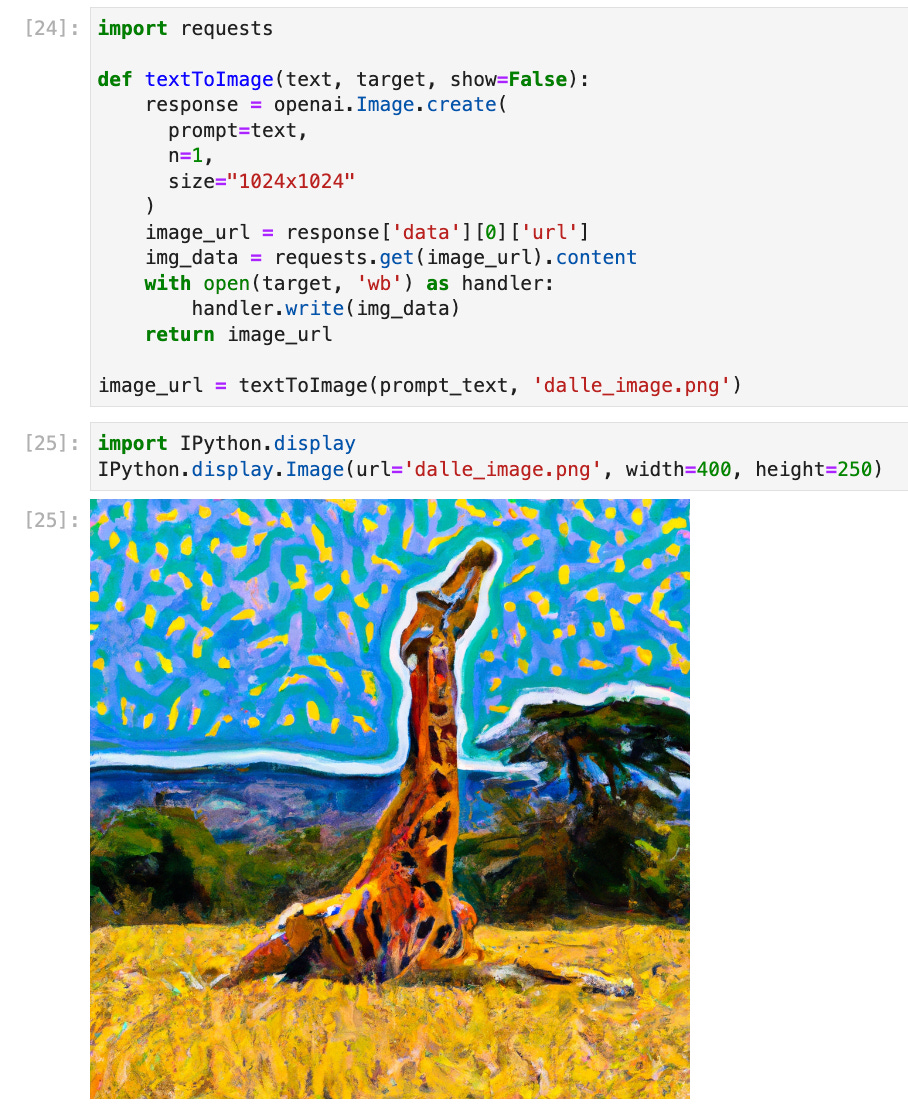
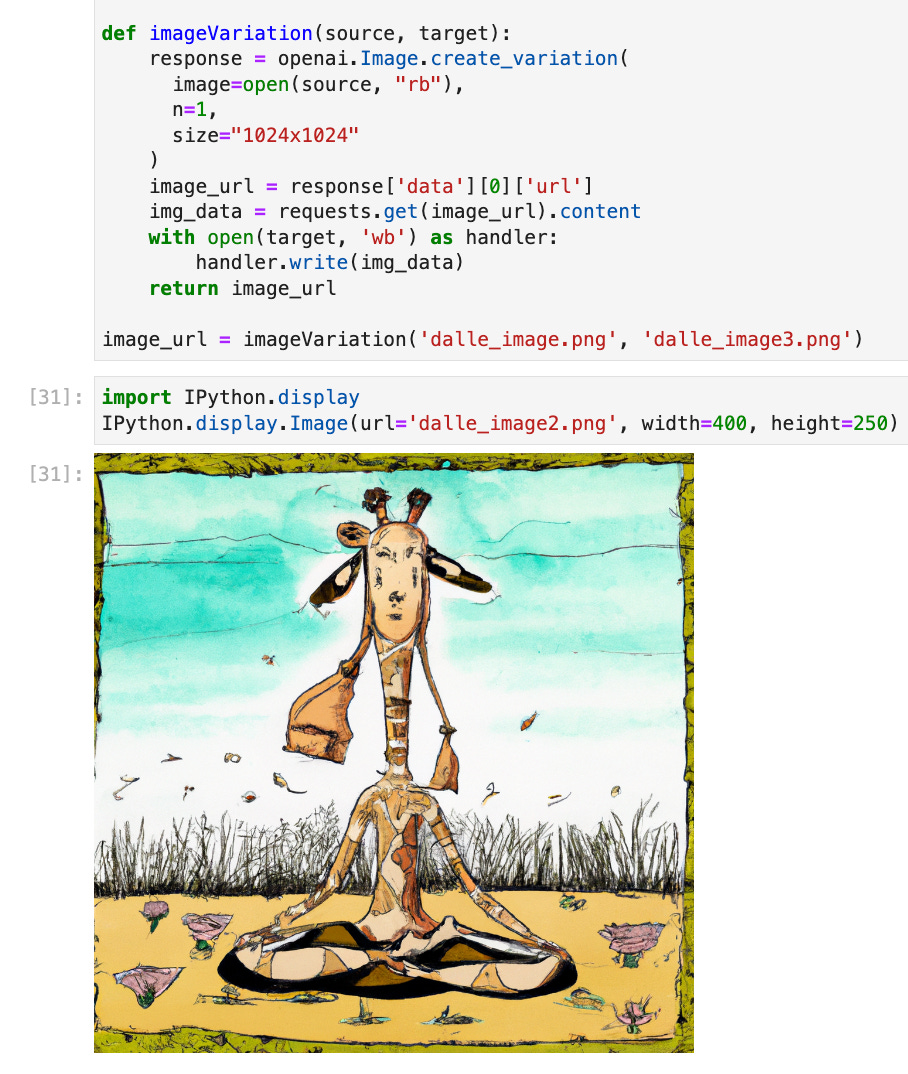
The DALL-E 2 API also allows for images to be edited with additional prompt information directed at at mask. This enables in-painting use cases. A further features is variation where a new variant image can be generated from an input one which allows for the creation of non-IP infringing new images. Variation is the key to a variety of SaaS AI art propositions like PhotoRoom mentioned earlier that take input images and modify them to produce modified artefacts for marketing purposes. Here’s a snippet taken from the same notebook showing an example of a variation generated by using the above image as input:
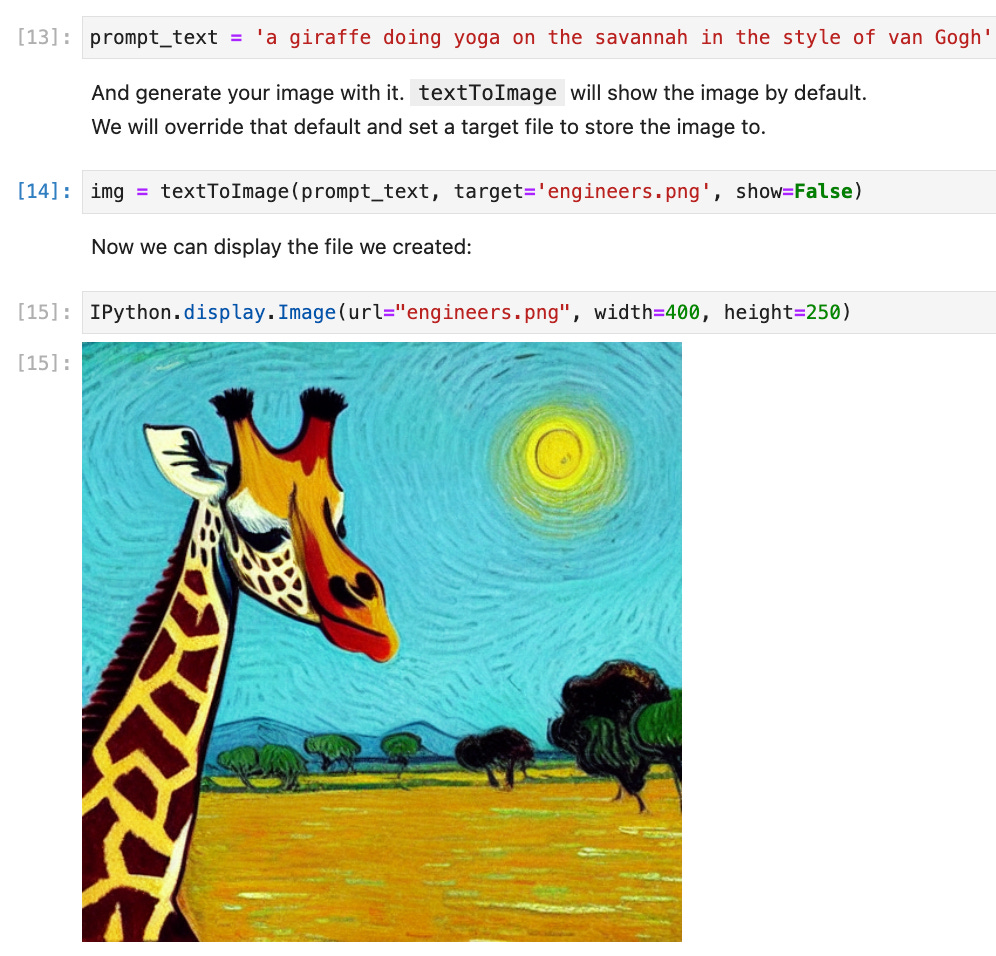
Stable Diffusion was the first AI art platform to offer API support. You can purchase tokens to use it through the DreamStudio web site. 1000 attempts cost about $10. The following code snippet adapted from another Jupyter notebook published here illustrates how to use Stable Diffusion to generate an image using the same prompt using a convenience function called textToImage which has been omitted for simplicity:
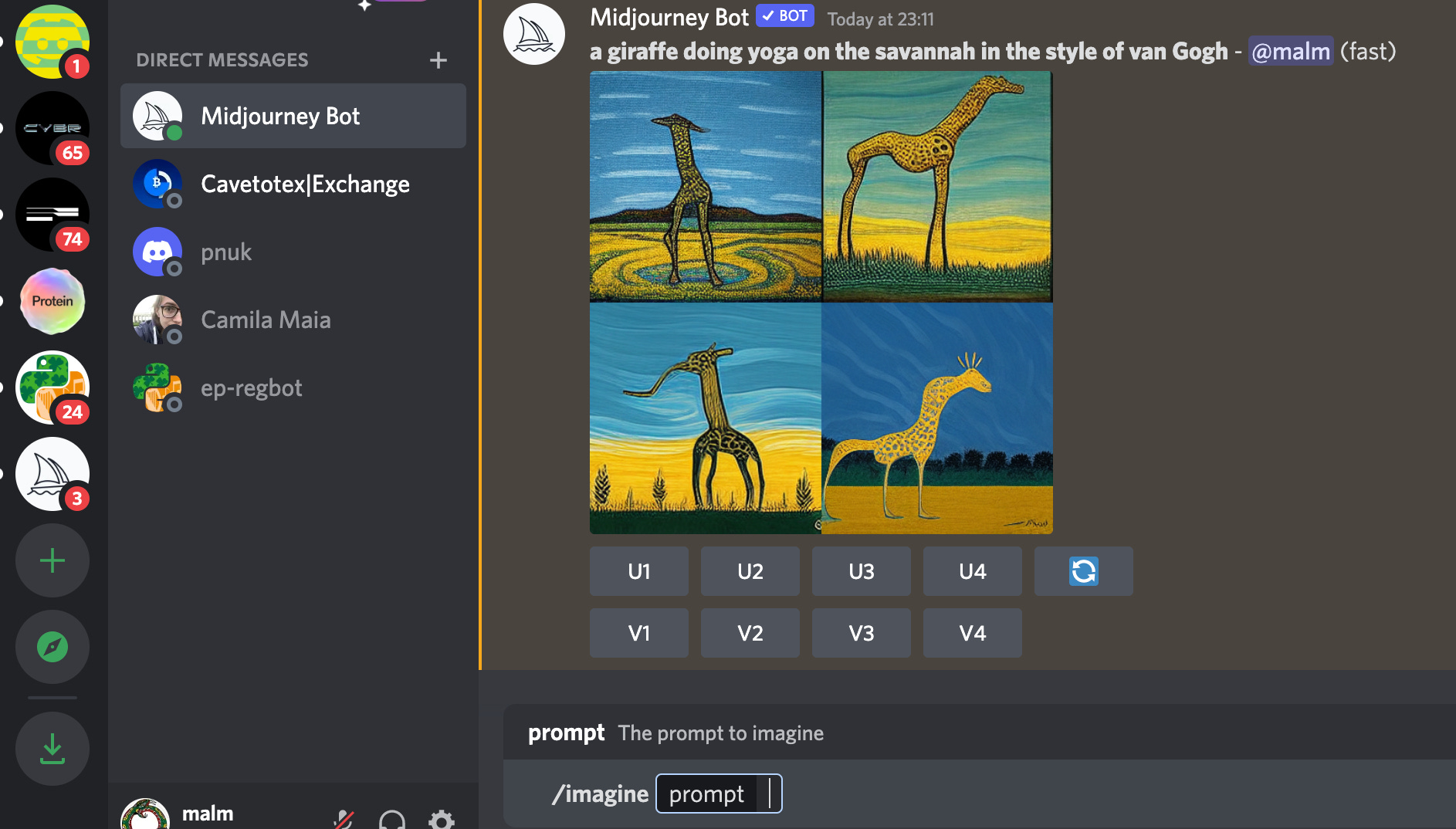
Midjourney on the other hand is only accessible via Discord. Once you sign up, you create an image using a /imagine prompt and then view your creations in a gallery via a user portal which has by far the best background animation of the big three. With Midjourney the same prompt yet again yields very different results generated from the same prompt introduced at the start of the article:
The non-deterministic results generated using these tools can be practically challenging to work with. The connection between the creation and the prompt is not fully explicable or even, as we have seen, uniquely expressive. It tends to encourage a more experimental test and learn creative workflow with lots of attempts to reach a good outcome. Interim outputs are preserved and the right image can be cherry picked afterwards in a rather similar fashion to the way old-school photographers operated. There is an uncanny lack of human connection in the generated images with unreal, disjointed faces and text often being rendered in the output. It certainly emphasises the artificial in the AI. This is easily demonstrated by using a prompt such as “a well functioning engineering team”. Improving outcomes around face and text integrated within images is a likely focus area for improvement and should get better over time.
There is active debate about the extent to which AI art platforms constitute a threat to the livelihoods of graphic creatives. Their existence certainly creates some jeopardy for creative artists and many have expressed concerns about their longer-term impact. AI art constitutes a new artistic technology that is bound to disrupt the art world as photography did before it in the 19th century. However, as with that prior innovation, the new will augment rather than replace the old.
Perhaps the bigger concern here relates to the general direction of travel. This topic was explored in another post entitled Storming the Citadel. It introduced the idea that AI convenience technology of this form constitutes a kind of Strangler Pattern for humanity. It is part of a general sweep dating back some 30 years or so that seeks to diminish the role and importance of consciousness and qualia in human experience. Arguably because human creating computing machines remain resolutely incapable of demonstrating consciousness while they appear to be progressing in leaps and bound in terms of demonstrating intelligence which we can define thus:
The ability to acquire, understand, and use knowledge
The hoisting of intelligence above consciousness and the belief that humans are a kind of legacy kludge in need of hollowing out and overhaul by AI are distinct traits with many in the Transhumanist movement. The eventual replacement of humanity by Artificial General Intelligence (AGI) is their ultimate goal. We need to exercise caution that advocating for AI art does not result in us extinguishing the very creativity which makes us human.
Summarising what we’ve learned, AI art has exploded in significance in the last year and shows huge promise. While impressive, the results remain uneven. The quality of images produced depends on crafting considered prompts which typically don’t resemble the way a human might describe them. Images with integrated text don’t seem to work well. Propositions like DALL-E 2 do offer scope for finessing the results with variation and in-painting capabilities. The technology is still relatively young with most of the generator platforms less than a year old. It is therefore still unclear what their eventual destination will be though we can expect lots of rapid development building on the basic 2D image form that is the focus today. The pace of evolution is inevitably going to be relentless as combinatorial advances dramatically shift the state of the art. We can expect improvements in the ability to generate images without requiring unnatural language as the tools adapt to understand human prompts better. Furthermore, these tools will continue to remain accessible on cloud platforms via increasingly expressive and powerful APIs. While there is rightly some concern about the impact of AI art on graphic artists as part of a broader concerns around technological unemployment, the ability to create art from natural language seems unlikely to displace humans completely and we should in any case strongly resist that endgame. A more probable outcome is that these platforms will be used to relatively rapidly generate sketch images as input into the creative process or to produce marketing collateral. As a bonus, the generated images will not be constrained by ownership issues issues. Therefore it seems likely the ability for users to create them will be integrated into social media platforms. This will be positioned as part of a broader consumer to creator pivot that has become a major preoccupation for many of those companies. Either way, the AI genie is out of the art bottle and can’t be put back now. It’s going to be a very interesting space to watch.